
How we stopped drowning in AI-slop PRs
Software Development Life Cycle (SDLC) methodologies were meant to avoid Human Slop, ie. miscommunications. You can address AI cognitive dissonance following those same principles.

In September‘25, we started spending hours in iterative loops of AI slop. AI just wasn’t smart enough to attack our complicated distributed algorithms. Four months ago, we were struggling with:
Reviewing large PRs that seem to be all over the place,
Creating brittle systems that seem to break with every change,
Gate-keeping areas of code that were ‘human only’, and
Keeping up with all the accelerated innovation.
We often will get into infinite loops being ‘totally right’, and then having AI do whatever the h*ck it wanted.
In the meantime, we kept hearing how Software Engineering teams kept multiplying their productivity month-over-month (MoM). But how? If your codebase is non-trivial, and you are working on fairly complex technology, this seems impossible.
In October’25 we started thinking about how to move from AI informed to AI lead, in the hopes of eventually becoming AI driven.
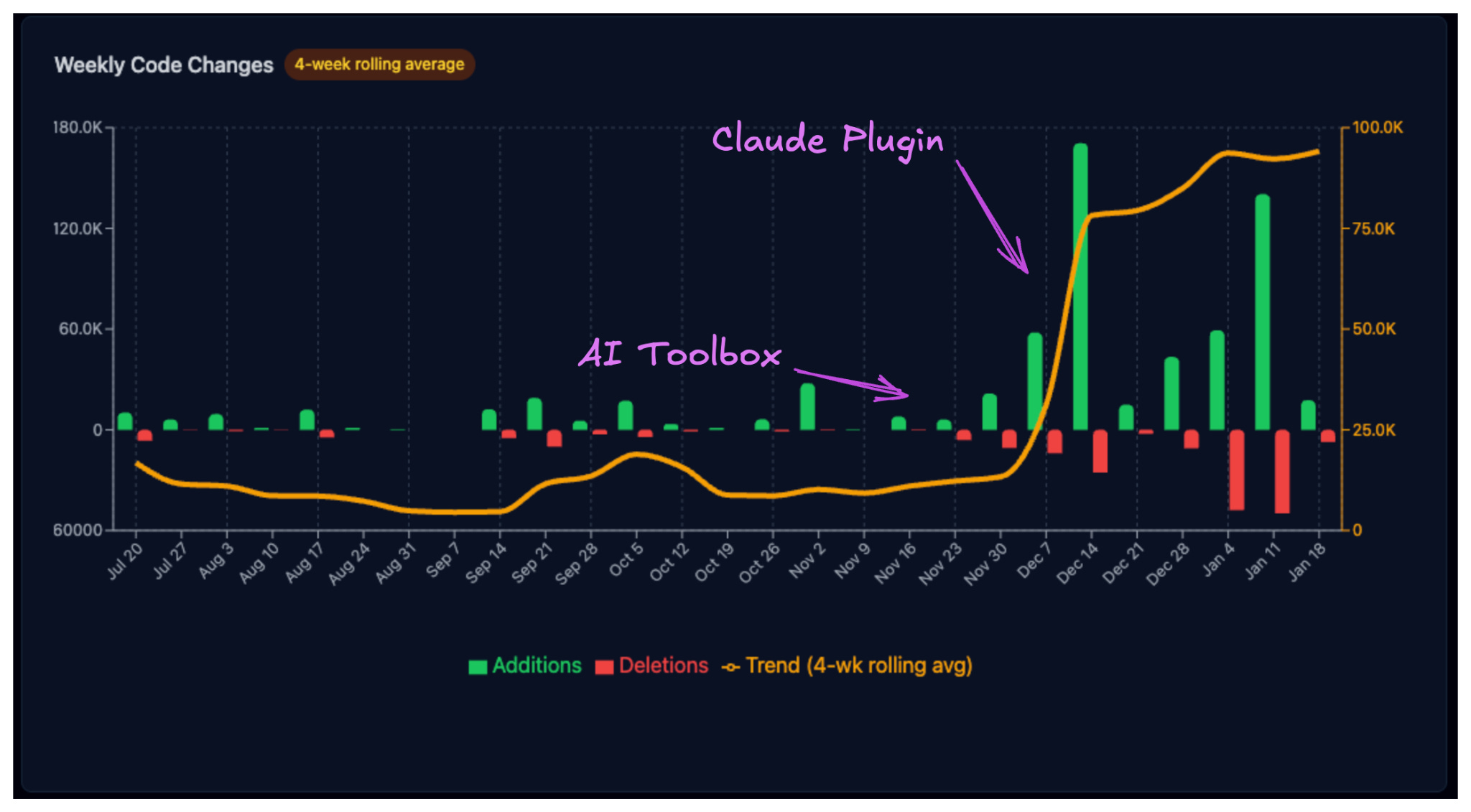
Since then, at desplega.ai, we’ve been doubling our productivity monthly. We did this by reducing the human-in-the-loop to 3 essential moments, and by adding structure to what was initially a set of unstructured prompts.
This article will give you an idea on how to start the path to get there yourself.1
First: Software Development Life Cycle (SDLC) applied to AI
AI coding platforms include a plan mode, a step in which they try to understand exactly what needs to be done and they describe how they’ll do it. That’s wrong. What and How shouldn’t be together, their objectives are different, the thought process is different, and also a mistake on defining What renders the How unnecessary.
That’s why SDLCs have stages with clear separation of concerns bolted in well structured communication mechanisms. The shift-left movement has proven that those steps are cost-reducing and increase overall speed for delivery. Hence, if you merge two essential parts of the process, imagine what you can expect?
First learning
Research first
You need to understand a problem in depth (research) before proposing a solution.
LLMs are compartmentalized. Your coding LLM and your GTM LLM, or your Notion one, don’t have holistic knowledge. Furthermore, they are limited by a context attention span (by size or focus). The same is true for the human reviewing, give them something too long, and they’ll also lose focus or procrastinate. That is our second learning.
Second learning
Split Into Atomic Tasks
You need to split tasks in self-contained steps that provide a small & structured context. Humans will review said context.
Now that you understand the problem, and you have smaller tasks, you need to deal with the compounding effect of introduced errors. The earlier you introduce an error, or your LLM assumes erroneously something and keeps that in their context, the higher the impact down the line.
At least for me, it happens often that I find myself switching LLMs for different problems or restarting a new chat, simply because they are on an infinite loop of wrong answers, they just decided wrong at the beginning. It’s not only coding, generating images or text has the same problem. Sometimes you need to just start fresh again, because the context built in a single step has gone awry. That’s the third learning.
Third learning
Don’t iterate, restart
You shouldn’t hesitate to starting from scratch at any step, if the output seems inaccurate. Particularly true during research and planning, as the quality of these compounds heavily.
If you apply this, your software engineers now will behave closer to Tech Leads, than to developers.
Second: Researching, Planning, and Implementing
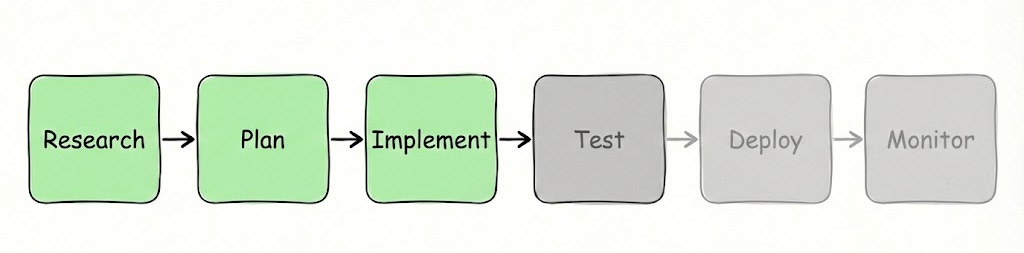
From those 3 learnings, we distilled three distinctive steps for our SDLC:
Research
Once you have an objective, you start a research on how your current solution, and existing libraries work. It could be a highly intensive process, hence we usually rely on multiple agents, MCPs, and other plugins that investigate the web, architecture, DB, infrastructure, code (even the deprecated one), libraries, docs, etc.
The output is a snapshot on the current systems available to achieve your objective. It’s a well crafted document that summarizes the state of the art at a given point in time. No more, no less.
You can store and version your research, and you can also stop relying on documentation altogether. This was key, now you have fresh research before a task, not outdated documentation that’s more difficult to maintain.
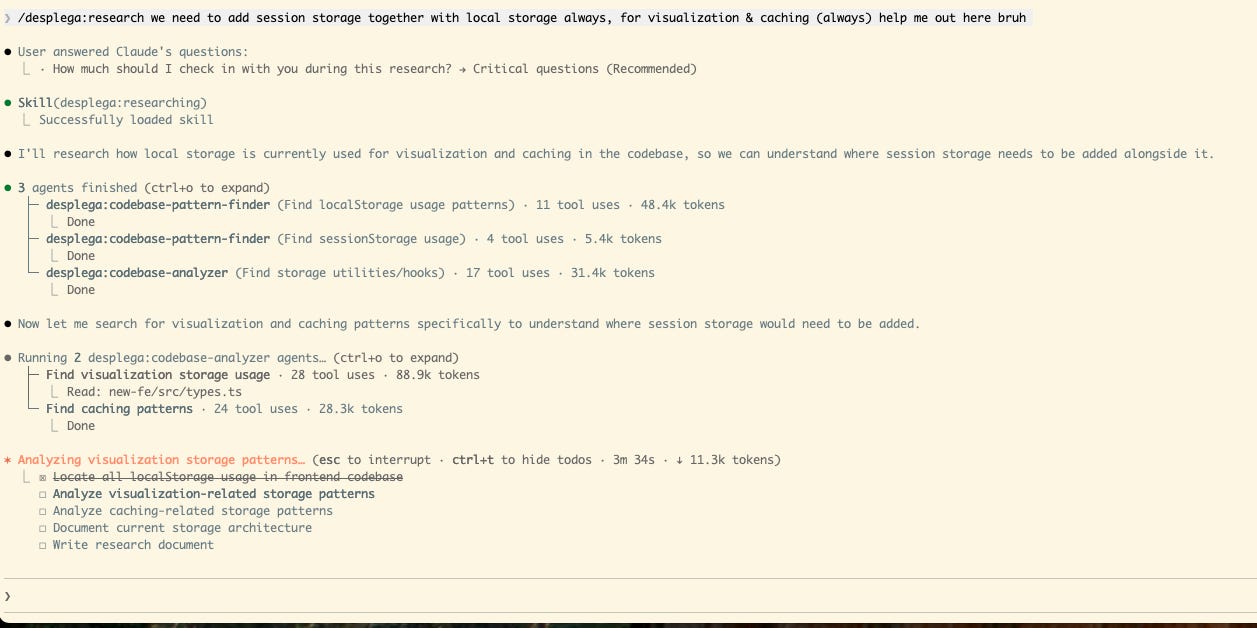
As humans, we review, edit and approve research. For example, you would remove deprecated libraries that don’t need updating, or corner cases that don’t represent business concerns.
Planning from one, or more, research
The tenet here is that you should be able to execute each step only with the output from the step before. That results in planning only requiring research documents as input. No more context, no more distractions, just plan.

The output from planning is a design document. It goes as low-level as showing key code changes. It will describe which algorithms and libraries it’s planning to use. This is all about the How.
As a Plan reviewer, the level of scrutiny you apply would be that of a document that you’ll hand down to an intern, for them to implement on their own.
No questions allowed. You are looking for decisions that deviate from how you envision the system in the hopes that you can detect edge cases, and lighten your code review phase.
Implement a plan
This is the “easy” part, if you did well before. Plans usually have phases, and each phase doesn’t require the context of the previous one, only the Plan. This is a direct result of how our plan was crafted, as you would do when defining a plan for your team, e.g. the plan should get implemented even if someone is sick, ooo or just got hired. Hence each step needs to be “atomic”.
Atomicity means that you can restart your coding agent with each implementation phase, keeping your context always at bay.
Our implementation agent will ask for impromptu snippet reviews, do multiple commits, and PRs, depending on the size of the feature or the practices of your team.2
Third: DIY or try one in 2 minutes.
As a starting point we opensourced our plugin, and agents, so you can use them as a guide here. If you instead prefer to try it in action, you can:
For claude-code
/plugin marketplace add desplega-ai/ai-toolbox
/plugin install desplega@desplega-ai-toolbox
/desplega:research <your research query>For anything else (skill.sh)
npx skills add desplega-ai/ai-toolboxThis will get you off the ground, but if you really want to leverage this power, you’ll need to learn and adapt it to your codebase. The mastery comes from actually understanding the patterns you follow in your own SDLC.
Feel free to reach out with questions, and have fun!
The-one-thing
Whatever you do, start using all the knowledge you’ve got from working in teams of hundreds of engineers. Because it doesn’t matter the size of your company, in a few months the dynamics are going to be that of having an unlimited number of colleagues, and you need to master how to deliver at that scale.
I’ve been hearing more and more companies that are 10x’ing personal allowances. They know how much of a gain there is, a single person in 5 minutes could save them years of investment, or decide to leave the company to do it on their own.
You can do it!
Together with Taras we wrote this series of articles to share different concepts we applied in this journey, starting with the mental model we used to tailor each step today. We will include Reviews, Quality Assurance, Security, Monitoring & Reliability soon, keep tuned!
We won’t talk today about testing, monitoring, and everything that comes afterwards, so that you really trust what’s produced. That comes next.