
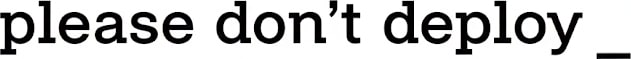
4 Leaps of Agentic Coding: Where do you stand?
tl;dr: An easy framework to understand where you are in your Agentic Coding transition, and the do’s and don’ts to progress in each stage.

In my last talk at CTO circle (Thanks, Marco!), I presented this model to 100+ Tech leaders so they could quickly help their teams grasp what they need to do to advance in their agentic coding journey. The model became such a hit, that I decided to share it in the hopes that we could have a unified vocabulary when looking into where we stand as developers.
The framework is intentionally simple:
Leap 1: From copy & pasting chatGPT to AI-powered IDEs.
Leap 2: From AI-powered IDEs to CLIs.
Leap 3: From CLIs in local, to agent swarms in the cloud.
Leap 4: From swarms, to self-learning and always busy coding agents.
Each leap is a series of brutal, distinct, cognitive loaded, new learnings. You go from non-stop “coding”, to an abundance of perceived “idle time”, to re-wiring one of your core mental models that held true for the past 20 years. And the worse part, once you finally feel like you’ve got a mild grasp of this new paradigm, you leap again.
You need to acknowledge the serious cognitive load we are exposed to as software engineers.
Traditionally, Software Engineers have been exemplary at keeping up with trends. We are avid readers, we explore new technologies constantly, and we pride ourselves on being innovators. We are known to be early adopters and quick learners that could move across industries flawlessly. So what’s happening?
The floor is shifting so fast that it’s not about keeping up with trends in a quarterly manner, it’s about what happened yesterday. In December, very few knew about agentic coding, in fact Taras & I were just starting to build our system. Today, it feels like if you are not using it, you are in the past.
This is, by any older standards, just bollocks.
When people are “so tired” after work nowadays, it’s more likely that their Germane Load is the one giving up, resulting in a false feeling of lack of accomplishment.
My advice: embrace it. These days learning for an hour pays off in minutes.
Here a simple framework with 5 stages, 4 leaps, and how to reach “Beast Mode”.
First: The 5 AI stages you’ll leap across
Nowadays teams are in one of these 5 stages. In fact, most teams are in Stage I, a few are tinkering with Stage II, and every CTO will tell you they are in Stage III. That’s OK!
The story goes as follows. Everyone starts by coping & pasting. That’s the C&P stage. Maybe your boss doesn’t know it, but you are doing it. You heard ChatGPT is awesome, so you copy a file, a stacktrace, maybe more, and you paste it in your personal ChatGPT account. You feel a bit dirty about it, but the result is amazing. After a few weeks, you start asking yourself, how can I do this with less C&P?
This is how it happens in each stage, you are always ‘trapped by an activity’. Each leap will be an attempt to remove that human bottleneck, so that you can go faster. Having said so…
Alas! Another activity will pop-up, one that you considered minor before, and that’s the target gap to fill with the next leap.
IDE & CLI stage
We make a distinction between using an IDE and a CLI, even though IDEs have background agents, inboxes, and cloud support. This is intentional, and the answer is very simple:
How much code you are reviewing on a daily basis implies how much you trust your Agentic coding set-up.
When using IDEs (heavily) you are still reviewing most of the code, so you are closer to an extremely powerful auto-complete, than to be working in a higher level of abstraction.
Nowadays, IDE’s provide ways to be less code centric, and move towards a CLI approach. This is why they are such a great intermediate step.
Antigravity Inbox setup (cmd+E) & Cursor Agents are an amazing way to start exploring what’s possible in that new paradigm.
CLIs, instead, force you to have a completely different relationship with your LLM. You will define criteria, steps, hurdles, and other mechanisms that your AI needs to overcome before it considers something done. That means the maturity of your AI Software Development Lifecycle will need to be greater, otherwise your team will immediately revert to an IDE. And they’ll be right to do so.
Swarms
Everyone is lying on the internet! They talk about their agents as if they were peers, that code for them, and they treat them as interns… liars!
Well, it’s not, sorry, you should be there, and you aren’t. But it’s understandable. It’s impossible to get there without doing all the homework in the previous stages.
Having an agent swarm means you now operate with your agentic coders in a fully asynchronous peer based communication style. In our case, that is through slack and github PR reviews. Every now and then, you’ll go deeper into a task, or tackle a specific project locally. However, 90% of the contributions will be coming from the cloud, and in some cases no-one will be reviewing them.
Beast Mode: what’s next.
We are working hard on this. It's what you hear as ‘back-pressure’, ‘success/objective functions’, ‘compounding’ or ‘self-learning’.
This is truly autonomous coding agents, where you set a direction, and they continue to make relentless progress in that direction, with you having weekly 1<>1s with them.
If you want to get into Beast mode, shoot me a DM.
Second: Becoming code agnostic
The first two leaps share a common thread: learning to disregard the code. This is the thing you were the best at. In fact, this is probably what made you progress. Either because you mastered how to diagnose issues in seconds or, because you were capable of truly understanding in depth the technologies you were relying on. Now it feels weird.
You feel like you are spending more time reviewing what the LLM did, than actually doing it yourself, and you have the confidence that you would have done it better. In fact, each bug you find, is a testament on how poorly LLMs work. What you have is confirmation bias.
You have an intern without their learning attitude, and your feel the intern is trying to get your job, and you keep reminding everyone that they are not you. Good news! They aren’t. Bad news! You’ll need to admit, sooner or later, that there is something they do better.
If you are lucky to get over this hurdle, then there is another thing that would come up: you need to choose wisely which technology to adopt. Here you spend weeks looking at all possible providers, and you decide to go with the one that is ‘easiest’. You also start thinking about how many quarters and training your team is going to need, and how slow or fast the roll-out will be. That’s the second wall: organizational inertia.
Finally, there’s a third and last serious blocker that results from combining confirmation bias and organizational inertia: lack of urgency. Basically, there are always more important, and urgent, projects to deliver. After all, we know how to solve those the old way, and we will tackle innovation next week, or maybe the week after… once we understand exactly what needs to be done.
Funny enough, after a few weeks of delay, you pat your own back, happy because now something new came out, and you tell your boss: “aren’t you glad we didn’t waste our time on Devin?” when in reality your organization just missed a chance to learn this when it was easier to understand.
The cognitive load from trying to force a one-size-fits-all solution for a problem you don’t know whilst trying to keep up with the day to day is a recipe for disaster.
You need to get out of the Copy & Paste hell fast, into a mode in which you are using an AI that has a persistent context of your codebase.
How to make the first leap:
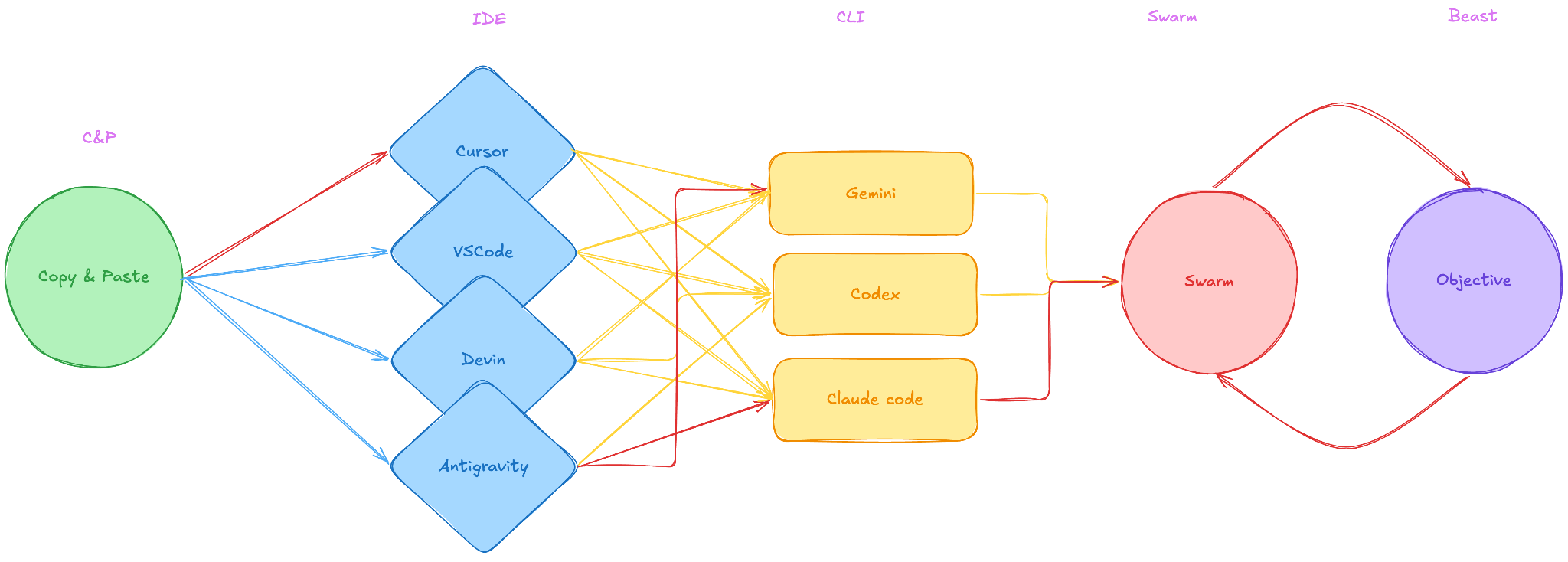
Break the standardization mandate
Choose any IDE, I recommend Cursor and/or Antigravity. Everyone should have different ones:LLMs have made it so that IDE set-ups are trivial,
Remember IDEs are an intermediate step, no need to customize or unify this.
From trying multiple IDEs the team will learn what good looks like.
Keep reviewing the code, you are not ready to fully trust AI, and AI is not ready for you either.
Do it now!
Block a day in your calendar per week to introduce new AI workflows in your development lifecycle.
Check how much progress you make after moving to an IDE, you won’t believe it. In the first leaps, you’ll probably 2x your pace within a day or less. The feeling is thrilling.
Leap II: CLI Revolution
It will take a few months, but eventually your team will master the AI IDE. And you’ll start hearing a few complaints.
Suddenly, some will mention how they spend so much time reviewing code before sending the PR, or how some people are sending PRs that are “horrible”. You will also hear how features that require more work, or go across repos, cannot be tackled by the planning mode, or how the background agents sound good in theory, but they don’t work because “something, something, something”.
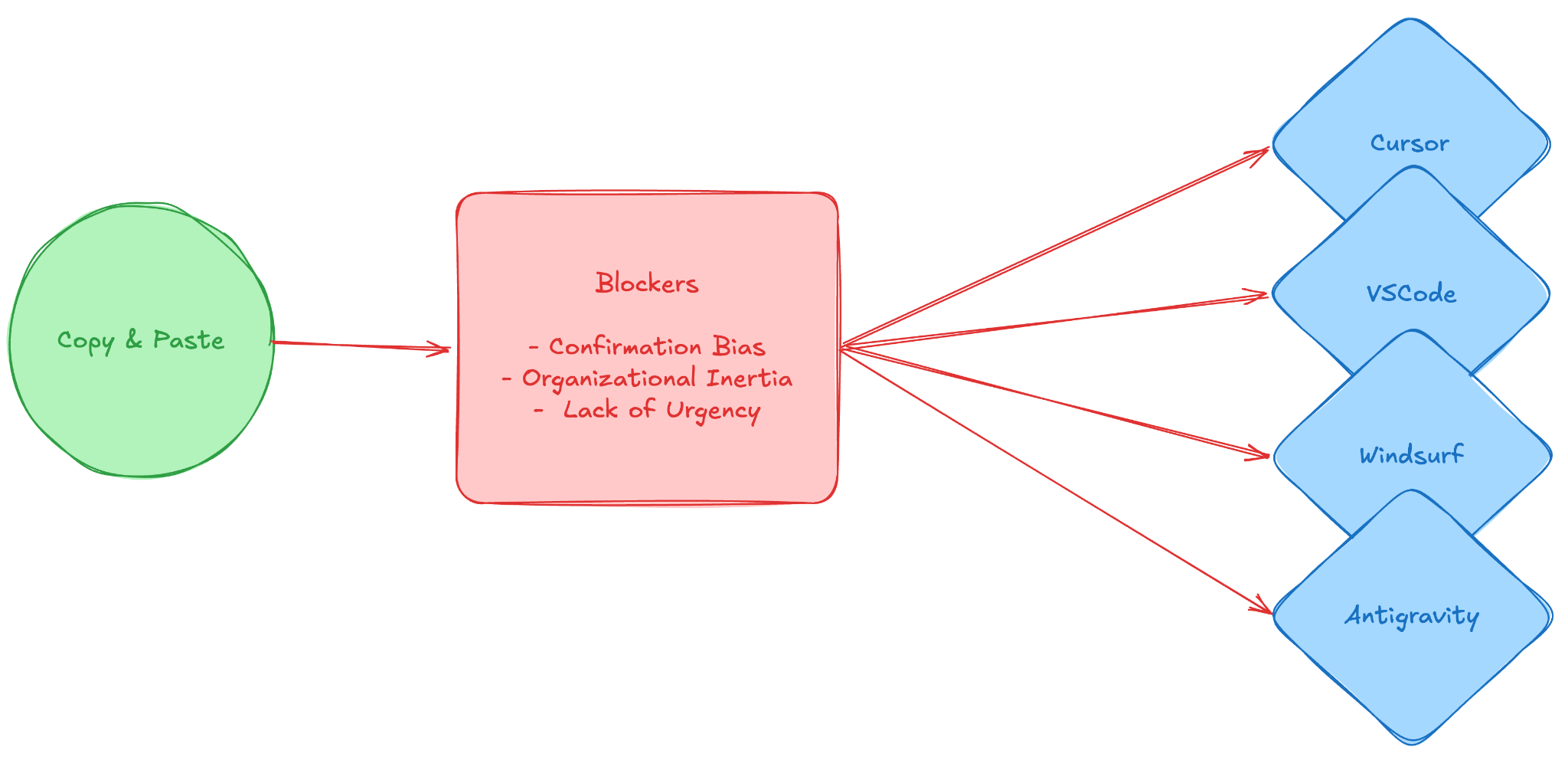
Whatever you are hearing, you can group complaints into:
Opaque system prompts
Suddenly the AI IDE cannot be customized as much as you’d like. In fact, you try the latest Codex 100.2x or Sonnet 3302.21 and it’s the same as that cheap QWEN, or maxmode. Everyone is revving about those models, for your team, nothing changed. The truth is probably it didn’t.
IDEs were important for you to understand how to work with AI when you didn’t have deeper knowledge on how it works. Now that you have a better grasp, the scaffolding they have added it’s limiting you, and this is more evident in their…Arbitrary frameworks
Each IDE has a different way of understanding your codebase, and it was optimized with a different customer in mind. They are very good at superficial things, but suddenly the team starts sharing “proven prompts”, or simply doing things manually because “it’s faster”. You are missing the command, skill, and agent layer from the CLIs, in a way that you can tweak faster.Proximity to code
“I don’t have time to review all the garbage it produced”. The key thing here is that your team is working still so close to the code, that they feel they need to review each line. That also makes it so that they usually “wait” for the LLM to finish, as some people used to wait while “it compiles”. They are not parallelizing enough which means…The inbox paradox
Moving from a real-time editor to an asynchronous “inbox” or terminal-output mindset feels unnatural. You are no longer coding; you are reviewing and dispatching. And to be honest, you are trying to review as little as possible.
Take the leap!
Yes, it’s that easy, here what’s holding you back is the actual IDE and your habits. If you just give any CLI a try, and you use a framework (you’ll finally develop your own, like we did). That would take you out of this loop in weeks.
The secret to get the best out of it: move to Antigravity first, start using their inbox feature, and then claude-code. That’s so natural that your team won’t even notice the transition.
Third: The “Idk what to do” phase
This is the most jarring transition. You will be moving from CLIs to full-blown Agent Swarms. You will eventually have background agents coding 24/7. The emotional blocker of this phase is the reality of making yourself redundant. The promise on the other side is scary, soon your team will be thinking: “Idk what to do.”

From CLI to Swarms
The emotional toll to start using agent swarms is massive. Your ICs need to relinquish the activity they love the most, reviewing code, and become TLs that review the work assigned, scoping and planning documents. This means the code won’t be reviewed until it’s too late, in the PR review phase at best. In some cases, not even then. Our advice in this step: focus on the message. Managers and TLs have known for decades that making yourself redundant is actually a strength in senior roles. You need to make High Output Management a mandatory read for all Software Engineers.
The second step is actually the technically challenging one. Blockers are centered on updating your Software Development Lifecycle (SDLC) to that of a team of 10x your size. That’s what it needs to be AI ready, and that means tackling the 4 stages of Semantic Distance while updating the jobs to be done by your team. We already wrote extensively about it, so here a short summary of what we’ve seen:
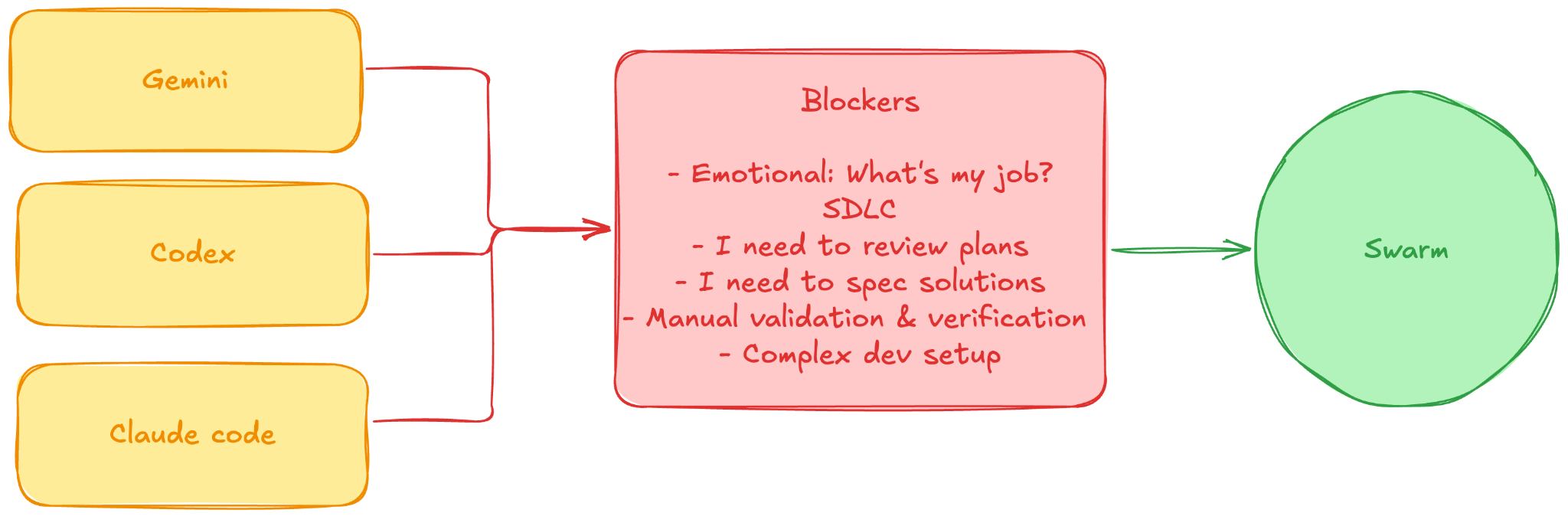
Defining specs & Reviewing implementation plans
Usually your team will start spending most of their time meticulously defining what the LLM needs to code. They will fall into the “Verschlimmbesserung” trap. They’ll start making something more and more complex in an attempt to make it better.Manual validation & Verification
Another classic trap, features get delayed because most of the review happens manually, from coding styles, libraries used to actual business functionality. In a worst case scenario, your team is doing a checkout of each PR generated by your LLM and testing it locally.Complex dev-setups
If you don’t have an agentic way to easily spawn your local dev, this is actually the most challenging part. Many will say they need to configure providers, or they don’t have ephemeral environments. It’s not a must, but it’s something you’ll need to address for sure within the next 2 leaps.
By the end, you’ll go from non-stop coding to an abundance of idle time. But it’s not a relaxing idle time; it’s an anxiety-inducing, high-cognitive-load idle time. You will feel every hour your swarm is not working, you are wasting time.
How to survive it
When we hit this leap, we spent weeks monitoring the swarm like anxious parents. The fix was realizing that validation, not verification, is the new job description. You have to stop reviewing the plans (the “how”) and start rigorously defining the evaluations (the “what”). You overcome this leap by investing heavily in robust linters, pre-merge hooks, automated E2E testing, observability, etc. Not just for humans, but also tools for your agents to understand what’s not working, and what are non-functional requirements for your business. This will become the majority of your work going forward, optimizing your machine that builds the machine..
Leap IV: Beast Mode
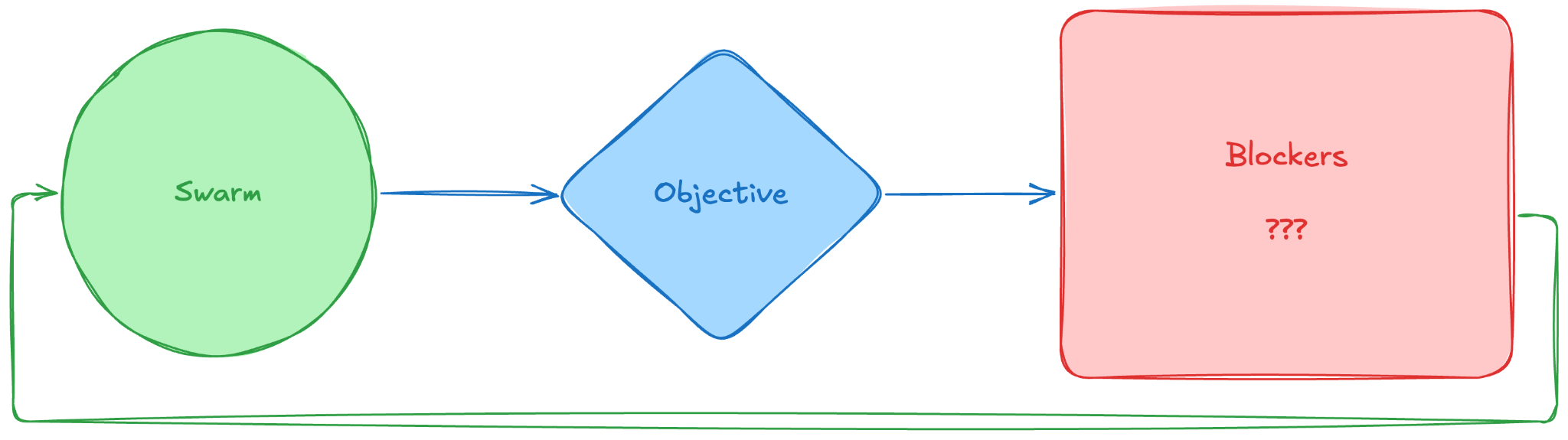
This is the frontier. We are here right now, and the playbook is being written as we speak. The premise: You aren’t assigning specific tasks to the swarm, you are defining a continuous Objective, a Northstar.
The objective could be as simple as the acceptable latency in an API response, or as complex as conversion rate in an onboarding funnel. It could involve defining health metrics around churn, or costs. And it needs to be a self-learning experience. The friction lies in setting up the feedback loop tightly enough that the swarm doesn’t silently destroy your business or rack up a $10,000 API bill in an hour trying to solve an NP-hard problem.
If your business is unique, your objectives are unique, hence your agent swarm will need to be unique. It’s now your Company Operating System
The swarm takes the objective, executes, hits blockers (???), self-corrects, and loops back automatically.
Hence, the only way “Beast Mode” doesn’t implode your company is if your Software Control (QA, Monitoring, Observability) is fluent in business outcomes. That’s what we are working on.
The-one-thing: Embrace the learning curve
The biggest shock of the Leaps isn’t how much you need to improve your SDLC, it’s the psychological toll of the idle time it creates and how it forces you to redefine your team’s work over and over again.
When you strip away the toil, the syntax-wrangling, and the manual testing, your engineers are left staring at a void of essential complexity. They are forced to think purely about product architecture, user validation, and business logic.
Don’t let your team fill this new idle time with micromanagement. Acknowledge the cognitive load.
Name the leaps. Push them through the discomfort of losing “proximity to the code”, and teach them how to be technical managers rather than coders. And above all, it’s time to look for help, you need to get the learnings fast, and they won’t come from your own company echo chamber.
That’s the way to get into Beast Mode.