
Our strategy to deal with LLMs prices
tl;dr: Don’t take shoveling advice from shovel sellers. We describe the strategies we follow in our internal agentic flows to optimize by cost, speed and quality.

November’25. Taras is very excited, agent-swarm is being born. I don’t get it.
We glance at each other, it’s 8pm. We are alone in a little office. We envision this as our Company + Agentic Operating System, capable of running our business while we sleep. Two questions stare at us:
Is this worth our time?
How expensive will this be?
The first one, albeit more complex, has a simple answer: Yes. We are a small team, and we noticed the ROI in hours. The second one, though… that’s the scary one. We know we are being sponsored by subscriptions. We have an implicit expiration date.
Around the same time, two conflicting trends emerge.
The culture of Tokenmaxxing with the advent of OpenClaw and Agentic Workflows, backed by VCs & top AI Labs. The concept is simple: move fast, burn things. You’ll see the benefits… eventually. It’s Circe’s dance.
“I could lift you up, I could show you what you want to see, And take you where you want to be” - Safe & Sound, Capital Cities.
The cautious tremor
Forward-thinking or not, these individuals know the moment won’t last forever. We know everyone has the same opportunity, we know we are not alone, and we have a more restricted budget. That limitation forces you to find efficient ways to scale your operations without creating business critical dependency.
5 months later, Q2’26 started. 3 things are converging into a sorrowed betrayal:
Github (copilot) & Anthropic (claude -p) slash their subscriptions (9x - 20x ↑).
Anthropic’s Fable with a 2x price hike, & removed from subs.
Minimax3 matches GPT-5.5 for coding tasks 6 weeks after GTP’s launch.
Corollary
”Cheaper” Models are weeks behind in performance, at a fraction of the price.
Here our strategy to have 40% deterministic steps in workflows/loops, how we leverage cheaper models, and how most of our budget still goes towards SOTA LLMs for “innovative” work.
First: Scripting the Toil
The concept of Eliminating Toil was formalized at Google as one of the main objectives for SRE teams. They were in charge of automatizing all those nuances that happen 10 times a day, in different shape or form. It’s been the obsession by Tech teams for decades, and the sole job of IT according to Nicholas G. Carr.
It’s cheap, efficient, and you can trust it will do the same, always. It does have limitations, though. To script something, you need to have done it before, very well, and understand the problem. This is how we do it:
Repo for our agent-swarm scripts, i.e. agent-works.
It’s fully controlled by the swarm, we don’t care. It includes testing, and whatever proof-of-work needed for the swarm to understand the scripts are valid. It’s a non-human repo that you can review if you please.Every few hours, agent-swarm optimizes.
We have methods to track and understand tasks, logs, and different techniques to evaluate success (think llm-as-judge, evals, OCEL tracking, etc). In this compounding loop, our swarm looks into repeated patterns in workflows and tasks, and generates scripts to optimize them.
The process resembles that of memories, you generate many scripts and use a fraction (~10%) very frequently. The key is that pay-off. Still too early to tell on our end.It’s not enough to be reactive.
We have adjusted our skills to generate workflows, and tasks, together with ourselves pushing to script everything we consider relevant.
Generating web-pages (the most basic example)
We don’t want hallucinations in content, we want factual retrieval.
We use litmus tests, llm-as-judge, linters, and reviewer agents… but
We have scripts that verify ‘links are valid’, ‘images exist’, ‘content is not repeated’, ‘style matches’, etc.
We trust the LLM will hallucinate less, but still it will.
There’s more to it though, as SWEs that love generalization, your scripts could be quite high level. In fact, they could radically change how you operate. For example, everyone simply says ‘loop!’ or ‘use Dynamic Workflows’, what they won’t show you is how to do it for less.
For us, one-off scripted workflows are the next bet. We can enforce, even for those ‘innovative workflows’ that the swarm uses the right models, scripts and agents for a single objective, without worrying about unpredictable cost.
The sad truth is workflows still represent a small fraction of our usage.
The good news is we consistently kept a ~40% deterministic ratio, & reduced dependency on frontier models for our workflows.
→ Two good reads on the topic [1][2].
Second: Cheaper and Faster could be Better.
I don’t have a Ferrari, I probably will never buy one, but if I had one, I wouldn’t use it to go for groceries, or my daily commute. I wouldn’t buy one because I don’t need that speed and comfort, I’m ok with a different solution. I wouldn’t use it day to day because, let’s face it, the trunk is too small, it scratches easily, and in general, it’s not meant for my day to day. It’s a luxury, and Veblen Goods are priced differently. My thesis: SOTA models are currently those goods for many.
“A corollary of the Veblen effect is that lowering the price may increase the demand at first but will decrease the quantity demanded afterwards”
We feel paying a premium makes the model premium, when in reality it may not be accurate for our use case.
The cost of running routine vs hard tasks in our agent-swarm, is intertwined with the actual price of the models (see below).
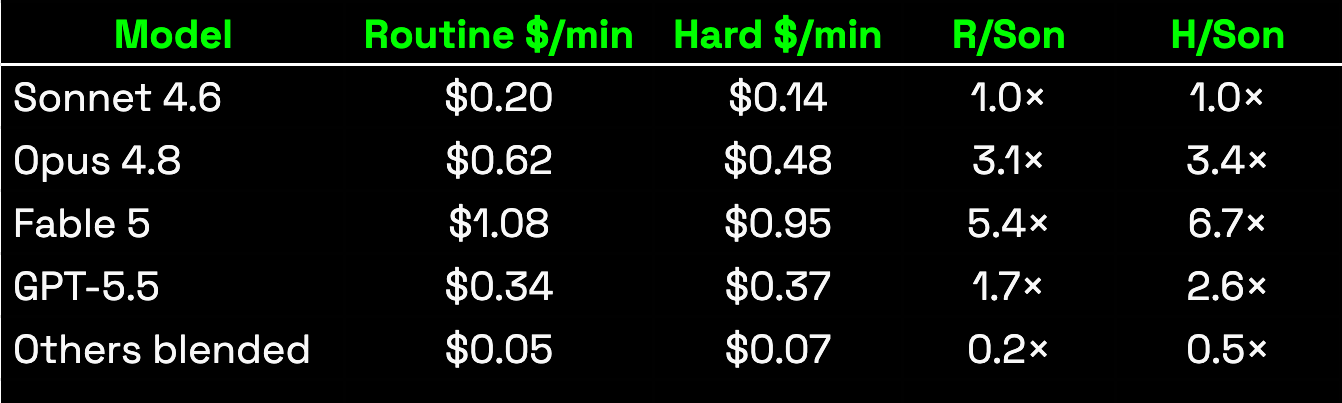
The minute being more expensive is a good indicator, but could be flawed. Thus, we look at the tasks as a whole:
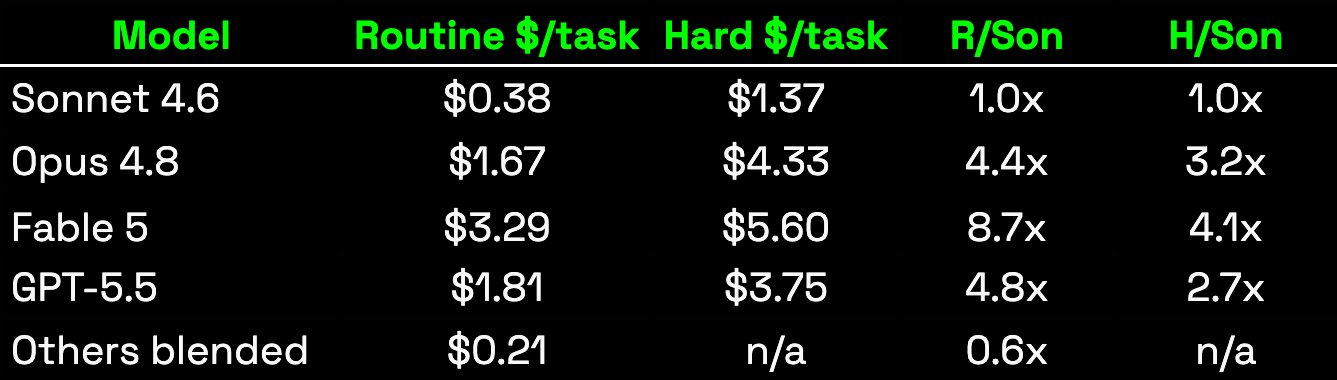
These tables are directional only.
We are working on a more formal benchmark internally. At this point this is the best result we can get from our existing logs.
Routine tasks are not only close in quality, but also cheaper & faster when done with less competent models.
We are starting to build automated ways to evaluate and adjust the models we use for what. However, it’s clear for us that the early strategy we implemented to use raw-llm or OpenCode/Pi as a harness for less intellectually challenging tasks is paying off.
For you to know:
We use DeepSeek & Kimi (OpenCode + Pi), for our GTM workflows.
We use GPT for coding and/or reviewing, (subs still hold here 🙂)
We use Grok for testing and UX.
~30% of our workflow steps are raw LLM calls.
We update these frequently, swapping harnesses and models. It’s been the other strategy to keep consumption low.
We still use Opus and Fable to boldly go where no man has gone before.
Third: What’s Hard? I don’t know. Exactly!
Our lead uses the most expensive model we are willing to afford. That’s because the lead is scoped with discerning what to do, and who should do it. It’s also the agent that kicks off our learnings. It has the broadest responsibility.
A simple idea at core: instruct your powerful model to be lazy; it implies not doing the same thing twice. That way, the powerful model turns into a pattern finder through your task logs, and it tries to relinquish from doing things as an LLM.

The sad truth: ~78% of our cost lives in Opus + Fable, down from ~88% weeks ago.
The good news: Advanced models are not ~10x the price, but closer to 2x.
Being smart here will allow you to get the most of your models.
The-one-thing
How do I train my workforce in this new thing?
The biggest learning we’ve got through this journey has nothing to do with how the system was built, but the motivation behind it. One simple rule: Our day-to-day shouldn’t change if we swap providers.
If moving between Codex, Cursor, Claude Code, OpenCode, etc, requires organizational effort, you are locked-in. If instead, you can transparently switch between solutions (harnesses, models, providers), the world is your oyster.
The good news: you already know how to introduce these changes. You did it for Cursor, Codex, Claude Code, Github Copilot, Devin… what a ride!