
!? Cloudflare: AI slop is a SaaS problem.
The same AI that floods internet with mediocre content is disregarding SaaS non-functional requirements

tl;dr: Quality, Reliability and Service are key executive concerns when selling your software as SaaS is entering the fast-fashion era .

Every couple of weeks a provider has an outage and we all commiserate about it. Your teams tell you it’s because slack/AWS/Cloudflare/SVB is down and we don’t have the redundancy, even though SOC2 insists we should have a recovery plan. Then the real exercise in futility starts.
I’ve been in multiple conversations where you start planning for a migration that would give you the redundancy and the quality standards that your customers wish for. The team invests countless hours planning a costly migration, integrating with new providers, to come to the realization a month later that leadership has forgotten about this priority. As a result, once this project gets delayed for quarters, two things would happen: (1) You’ll fire your Head of Engineering the next time this happens, and (2) Your team won’t believe you next time you say this is a priority for the business.
Spot the fallacy: Internet shouldn’t be down if a (major) provider has an outage.
Before doing the math together to figure out how much of a real issue this is for your business, and your providers, let’s look into the last five years of incident data to see if this problem is getting worse.
First: The study.
I took the liberty of compiling all self-reported incidents from Cloudflare, DataDog, Github, Google Cloud, Zoom, and Slack. I focused on providers with transparent incident reporting. Surprisingly many major providers cap their public disclosures, or have limited historic data, making accurate comparison impossible.
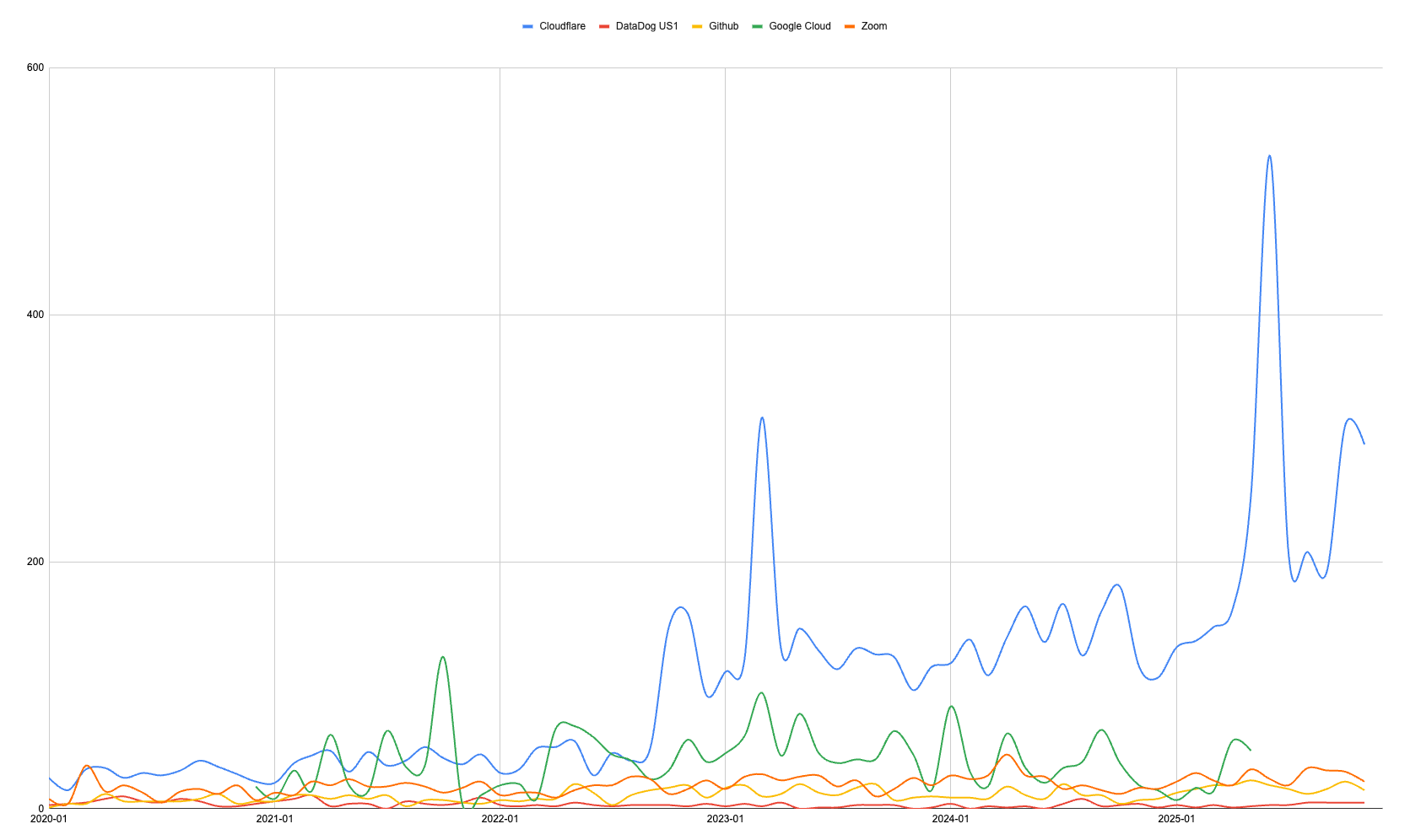
The curve for Cloudflare speaks for itself. They went from well below 50 incidents a month in 2022, to over 100 during the last 3 years. You could argue they launched multiple products, expanded their user base, and they became the de-facto solution. You could also make the case that they may report incidents multiple times, if those affect several solutions. However, I think we can agree on 2 things:
Peaks & valleys from Google Cloud kind-of map those from Cloudflare 🤷🏽♀️,
Other equally important platforms saw incident increases, too.
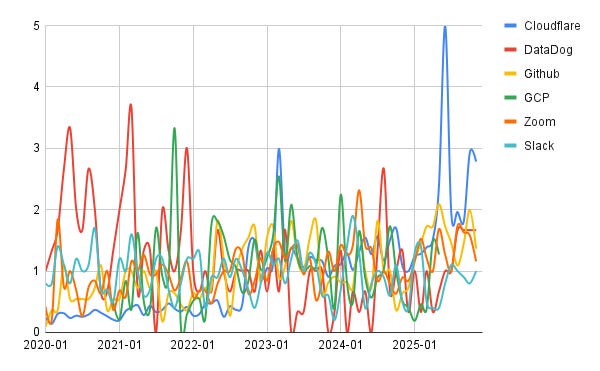
The first one, it’s just hearsay, so I’ll skip it, it’s just a curiosity. The second one is much more interesting. If you normalize the curves, it’s clear that while most sustained some degree of increase, particularly Github, Datadog, and Zoom, they didn’t double incidents. Actually, Datadog & Google Cloud improved significantly since 2022, and both seem to be trending downwards. Kudos to them!
In 2011, Blackberry had a 3-day major outage affecting their private network. They went from peak revenue in 2011 (~20Bn) to ~7Bn by 2013. That’s mostly because their customers had multi-year contracts, they probably forgave the issues, but didn’t forget. Their Quality & Reliability moat was eroded after such an incident.
The Blackberry case study is categorical, you should consider that when your customers evaluate what providers to use next, reliability and quality will bite back, hard.
It’s never about the commitment shown by Executives, it’s about trust. In that scenario, explaining what happened is not enough, and asserting that you care, won’t be enough.
Second: Countermeasures
Unfortunately, the services provided by Cloudflare are not easy to replicate. It’s closer to having two ERPs or CRMs, in case one fails. Do you know someone that does so?
No company has Salesforce with a transparent fallback to Hubspot, or viceversa. It’s true that you could build it, and both platforms allow you to have setups running 24/7 to extract and populate data. It’s also true that your customers wouldn’t notice if you are using SFDC, Hubspot or Attio, at any given point in time. However, most organizations wouldn’t invest the resources required for this to happen. In fact, it’s so difficult with a single platform, that teams usually have RevOps experts pulling the data from their own business. It’s their built-in customer lock-in methodology, their moat.
Cloudflare, Google Cloud, Azure, AWS, etc, are in a similar situation. You can have redundancy, and your tech teams can build towards that horizon, however for a growing company this quickly becomes prohibitively expensive in time and resources.
It’s usually because Tech leaders are builders, that they rally behind the idea before evaluating the ROI for such long term investments. As an Executive, the question you need to answer is simple:
Would avoiding a 1 day outage be worth 2x my tech infra costs?
Third: The math
Sit down with your Account Management and Customer Support team, they’ll need to help you answer the following questions:
Do we have customer agreements that penalize us due to SLAs?
Even worse, many corporations will include clauses that allow them to cut ties with you immediately if your uptime is below 99.99%. That means your largest accounts will get a free ‘get out of jail’ card. Or, at the very least, you’ll need to have a very uncomfortable conversation.How much new business will we lose during that outage?
If you lost a whole day to onboard new users, how would that actually look like from a P&L perspective. This is true for C2C/B2C solutions, much less for B2B SaaS.What’s the sentiment of our existing customers after an outage?
This one is tricky, most people will be understanding at first. They probably were faced with similar issues from other providers, so they will actually let it slip… until…What happens when someone approaches them with a solution that promises better Quality?
You need a proactive playbook. In an AI world where features aren’t a key differentiator any longer, the non-functional requirements become key.
It’s Quality that rules, and outages are the biggest expression of failure.
I’m confident if your company is an SMB, or an early stage startup, you can safely ignore the redundancy idea. The only question you may ask yourself is: should I change providers?
the one thing
Quality, Reliability and Service are a key competency for your team. It’s not because the absence of them will mean you’ll lose business immediately, it’s actually because once a user uses your solution, they get savvy.
Customers learn quickly about your solution, competitors, and alternatives. They will quickly consider a switch when price is not an issue, if they have the promise of something that works ‘a bit better’. That’s all the push they need to do that seamless transition, and explain to their superiors how they have done the smart choice. Above all,
Don’t fire your head of engineering!
They did the right thing for the business.